Using Spark and Kafka for the 2016 Riot Games hackathon
Riot Games recently held a hackathon, from September 20th to 24th, at their headquarters in Los Angeles. I was invited and I’m going to tell you what my team ended up doing!
Riot Games is the developer of League of Legends (LoL), a multiplayer online battle arena (MOBA) video game inspired by the popular Warcraft 3 mod DotA. Basically, you have two teams of five people battling around until one of them wins.
A few weeks prior to the hackathon, all the people invited were thrown into a Slack channel to kick ideas around and form teams. Early in this process, I suggested the idea of displaying the winning probabilities of each team in game and in real time.
I was joined by Anthony and Shawn to form the in-game winning probabilities team, for lack of a better name.
This post will walk you through the different parts of our project, the technologies we leveraged and how we used them. You can find the full repo on GitHub.
Problem specification
The problem we were trying to solve was the following: given a state of a game at some point in time, predict which team is going to win and with what probability. This can also be viewed as a classification problem: given X features representing the state of a game, predict the winning team label.
ETL
The first part of the project consisted of gathering as much game data as possible. Thankfully, Riot Games exposes an API to interact will all LoL-related data: https://developer.riotgames.com.
Amongst all the endpoints, one stroke us as particularly useful: the match endpoint. Indeed, it contains all the information relative to a single game such as the champions the players picked, each player’s competitive history or the winning team. Moreover, it contains timeline data: a summary of the game state for each minute in the game like the numbers of monsters killed by each player, the number of other players they killed or their gold.
From that data, we were able to compile the most basic list of features we wanted to integrate into our classification model:
- the champion each player picked
- the number of kills / deaths / assists for each team
- the gold accumulated by each team
- the number of monsters each team killed in game
- the sum of each player’s level for each team
- data relative to each player’s competitive history (how well they had been ranked in the past)
- the game time elapsed to get to this state
All we needed to gather this data were game ids to give to the API so we could get our match data from the API. Fortunately, one of the organizers from Riot (shoutout to Tuxedo) compiled a list of 30k game ids coming from ranked games (the way to play competitively in LoL) in Diamond (a division of ranked play).
Using this list, we got the matches data from the API and formatted it as a big old csv. This was all done in a small Scala app we called etl. For our custom needs regarding parsing, we used circe which is a great library for parsing JSON in Scala.
Model building
Once our dataset was built, we used Apache Spark and the latest pipeline API of MLlib to build our classification model.
We chose random forest as our classification algorithm because of its ability to reduce overfitting thanks to its bagging of features and examples when building different decision trees. Plus, its decision trees are independent so they can be trained in parallel.
Unfortunately, we didn’t have time during the hackathon to tune our hyperparameters. Nonetheless, we obtained pretty good performance anyway with 75% accuracy for our classifier.
We were also able to find out which components of the game take a team closer to victory by analyzing the importance of each feature in our model. The following are the 4 most important features:
| Feature | Importance |
|---|---|
| deaths | 11.1% |
| kills | 9.8% |
| tower kills | 7.4% |
| dragon kills | 6.9% |
The code regarding the construction of the model is in the model project.
Making predictions using Spark Streaming and Kafka
Now that we had our model, there was one piece left: interrogate it with data coming from a game being played in real time to make predictions. For this part, we relied on Spark Streaming and Apache Kafka.
The application is simple: it reads from a Kafka topic where the game state is continually being sent to by the client, makes a prediction using the model we previously built, and write its prediction to another dedicated topic. The predictions are then read by the client and displayed as we’ll see in a second.
Writing the predictions back to Kafka was done using spark-kafka-writer which is a small library I
wrote which lets you write Spark data structures (only RDDs and DStreams for
the moment) to Kafka.
The code for this streaming application is in the streaming project.
Client
I only have a broad understanding of what’s going on in the client since I wasn’t involved as much so I won’t go into to much details.
We use Overwolf to retrieve a few bits of information from the game like the list of players and their champions and to display our win percentages.
We also capture game data being displayed in the LoL client thanks to LeagueReplayHook which is maintained by Matviy, another guy who was at the hackathon, shoutout to him!
The result takes the form of an overlay on the LoL client in spectator mode displaying the probabilities of winning for each team:
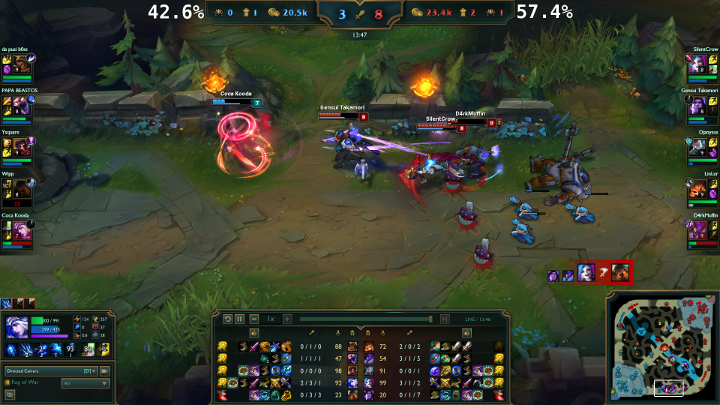
Conclusion
We managed to end up runner up at the hackathon which is a pretty amazing feat given how great the other projects were!
The project won’t end here however as we’re planning on improving a few things especially regarding the model. Indeed, we’re working on improving its accuracy by expanding the pool of matches we learn from (we only had 30k ranked diamond matches) and adding new features such as picked champions, type of killed dragons or type of killed towers (outer, inner, etc).
We also have quite a lot of work to do client-side since the last patch (6.21) broke the real-time capture of information in the client and a few things are not being tracked such as baron kills.
We’re also participating in the LoL Overwolf App Dev Challenge.